Monitoring replication lag in a Kafka cluster is crucial in order to ensure data availability and durability. Replication lag occurs when the replicas of a partition are not in sync with the leader, which can occur due to network delays or a slow follower.
When replication lag happens, it means that the follower replicas are not able to keep up with the writes being made to the leader. This can cause the replicas to fall behind the leader, which can result in data loss if the leader broker fails before the replicas have caught up. Furthermore, it can also cause inconsistencies in the data stored on the replicas, which can lead to issues when the replicas are promoted to the leader.
There are several causes of replication lag:
- Network Latency: If the network between the leader and the replicas is slow or unreliable, it can cause replication lag. This can happen if there are high levels of network congestion or if the network is not configured correctly.
- Disk I/O: If the replica’s disk I/O is slow or saturated, it can cause replication lag. This can happen if the replica is running on a slow or overloaded disk, or if the replica is running on a machine with limited resources.
- CPU Utilization: If the replica’s CPU is overutilized, it can cause replication lag. This can happen if the replica is running on a machine with limited resources or if the replica is running other processes that are consuming CPU resources.
- Memory Pressure: If the replica is running low on memory, it can cause replication lag. This can happen if the replica is running on a machine with limited resources, or if the replica is running other processes that are consuming memory resources.
To monitor replication lag, one can use kafka-consumer-groups command and check the lag for each partition and replica. The lag is the number of messages the replica is behind the leader. Monitoring replication lag regularly is important to detect and resolve issues as soon as they arise.
To mitigate the replication lag, one can:
- Increase the resources available to the replicas such as CPU, Memory and disk I/O
- Optimize the network between the leader and replicas
- Tune the replication factor and consistency guarantees
- Use auto-failover mechanism which automatically elect a new leader for a partition when the current leader goes down.
In summary, replication lag is an important aspect to monitor in a Kafka cluster. It can impact the availability and durability of the data stored in the system. Monitoring replication lag regularly is important to detect and resolve issues as soon as they arise. And there are several ways to mitigate it.
Auto-failover mechanism
An example of an automatic failover mechanism is the Kafka MirrorMaker tool provided by Apache Kafka. This tool is designed to create a replica of a source Kafka cluster on a target Kafka cluster. In the event of a broker failure on the source cluster, MirrorMaker can automatically promote one of the replicas on the target cluster to be the leader for the affected partitions.
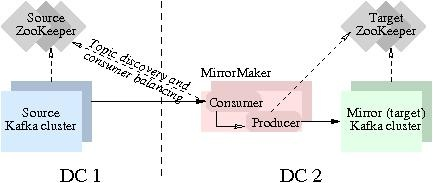
This allows the target cluster to continue servicing read and write requests, even if the leader on the source cluster goes down. This not only provides high availability but also minimizes data loss, as clients don’t need to be aware of the leader change.
Here is sample configuration example for MirrorMaker
# list of brokers in the source kafka cluster
source.brokers=192.168.1.100:9092,192.168.1.101:9092,192.168.1.102:9092
# list of brokers in the target kafka cluster
target.brokers=192.168.2.100:9092,192.168.2.101:9092,192.168.2.102:9092
# list of topics to be mirrored
topics=topic1,topic2,topic3
# number of threads to use for mirroring
num.streams=3
# replication factor for mirrored topics on the target cluster
target.replication.factor=3
# enable automatic failover
auto.failover.enabled=true
# time interval to check for broker failures
auto.failover.interval.ms=10000Confluent’s Kafka-clients library
Another example of automatic failover is Confluent’s Kafka-clients library. This library provides an automatic failover feature for Kafka consumers. In case a consumer loses its connection to the leader broker, the library will automatically try to reconnect to another broker that has the same partition, allowing the consumer to continue reading data from the partition, even if the leader broker goes down.
- First, you would include Confluent’s Kafka-clients library in your project by adding the appropriate dependency to your build file (e.g. pom.xml for Maven, build.gradle for Gradle).
For example:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.2</version>
</dependency>
2. Next, you would create a Kafka consumer object by instantiating the KafkaConsumer class and providing the appropriate configuration, such as the list of brokers to connect to, the group ID, and the list of topics to consume.
3. You would then set the enable.auto.commit property to true and to “enable” the automatic failover feature you should set the property reconnect.backoff.ms to a non-zero value, this will cause the consumer to periodically attempt to reconnect to the cluster and it will automatically failover to a new broker if the current broker goes down:
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.1.100:9092,192.168.1.101:9092,192.168.1.102:9092");
props.put("group.id", "myGroupId");
props.put("enable.auto.commit", "true");
props.put("reconnect.backoff.ms", "10000");
// props.put("auto.commit.interval.ms", "1000");
// props.put("auto.offset.reset", "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);4. You can then subscribe to the topics you want to consume from and poll for new messages using the poll() method.
consumer.subscribe(Arrays.asList("topic1", "topic2", "topic3"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// process the record
}
}5. If a broker goes down, the library will automatically try to reconnect to another broker that has the same partition, allowing the consumer to continue reading data from the partition, even if the leader broker goes down.
Additionally, you may want to set some configuration properties like session.timeout.ms, max.poll.interval.ms and heartbeat.interval.ms to ensure that the consumer can detect a broker failure in a timely manner and to prevent it from being kicked out of the group because of being considered as dead.
In summary, automatic failover mechanisms are designed to ensure high availability and minimize data loss by automatically electing a new leader for a partition when the current leader goes down. These mechanisms can be implemented through tools such as Kafka MirrorMaker or libraries such as Confluent’s Kafka-clients.